 .
.2021-08-30
< view all posts理想情况下,流处理引擎为每个key都预先分配好滑窗,在有数据到达时数据就可以直接落到对应的窗口中。但是实际情况下,资源是有限的,因此Flink不会预先创建空窗口,而是采用懒构造的方式,仅当一个key有对应数据到达时才会创建窗口。
因此Flink滑窗的创建是向前追溯的——首先创建当前时间所对应的那个窗口,之后向前追溯,补充之前因为懒策略而没有创建的所有窗口。
以源代码中 SlidingProcessingTimeWindows 这个类为例,它的窗口创建过程是这样的:
@Override public Collection<TimeWindow> assignWindows(Object element, long timestamp, WindowAssignerContext context) { timestamp = context.getCurrentProcessingTime(); List<TimeWindow> windows = new ArrayList<>((int) (size / slide)); long lastStart = TimeWindow.getWindowStartWithOffset(timestamp, offset, slide); for (long start = lastStart; start > timestamp - size; start -= slide) { windows.add(new TimeWindow(start, start + size)); } return windows; }
示意图如下,数据在t0时刻到达后,Flink除了创建 (t0, t0+size) 这个窗口之外,还会在循环中不断向前补充创建需要追溯的窗口:
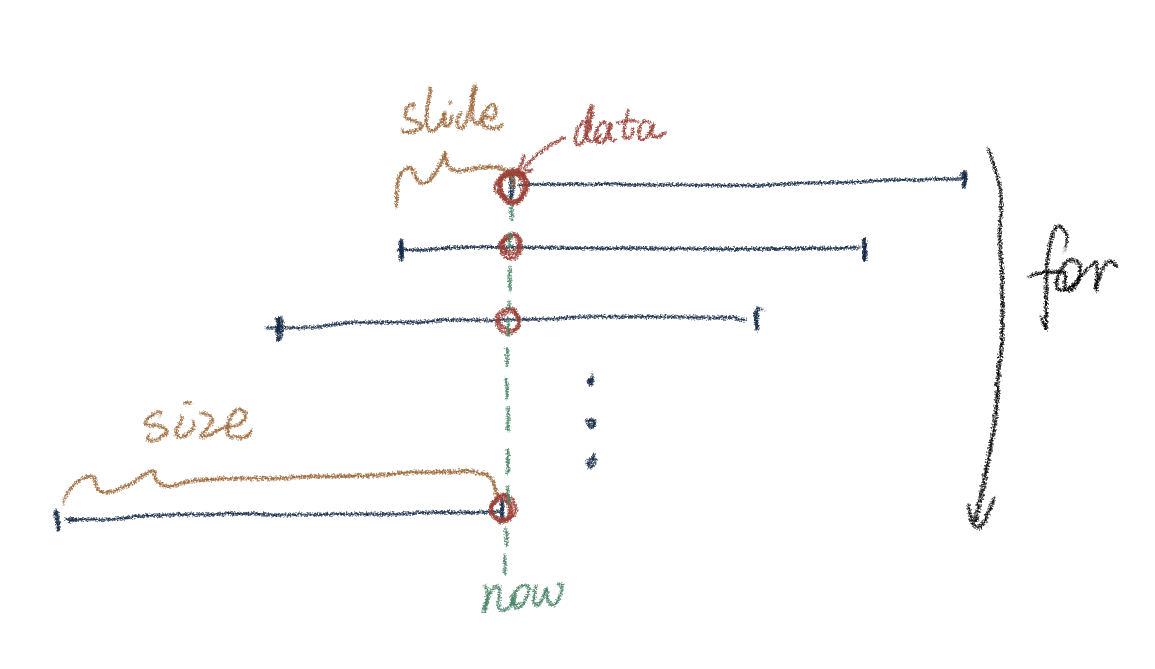
在继续有新数据抵达时Flink采取的窗口构建策略是相同的,依然会做同样的循环和向前追溯,多了一步是将准备创建的新窗口和已有的窗口进行比较,合并相同的窗口,避免重复创建。
此过程可以参考源代码中 WindowOperator#processElement 方法:
for (W window: elementWindows) { // adding the new window might result in a merge, in that case the actualWindow // is the merged window and we work with that. If we don't merge then // actualWindow == window W actualWindow = mergingWindows.addWindow(window, new MergingWindowSet.MergeFunction<W>() { @Override public void merge(W mergeResult, Collection<W> mergedWindows, W stateWindowResult, Collection<W> mergedStateWindows) throws Exception { // ........ // merge the merged state windows into the newly resulting state window windowMergingState.mergeNamespaces(stateWindowResult, mergedStateWindows); } }); }
从上面对滑窗生成机制的分析可以看到,Flink滑窗为每个滑窗都维护了一个独立的窗口状态。
例如定义了一个长度(size)为5分钟,步长(slide)为1秒的窗口,那么在一条新数据到达时,会同时有 5min/1s = 300 个窗口被创建,且每个窗口都维护一个独立的状态,各窗口间的重叠部分导致了资源的浪费。
这个机制具体会导致以下几个问题:
1、如果数据产生较为稀疏,会有许多窗口具有完全相同的输出,导致下游许多不必要的IO
2、和1类似,许多窗口各自保存一样的状态是对内存的浪费
3、窗口在创建和销毁时的高并发导致高CPU负载,这导致实时(低延迟)的窗口几乎不可能用Flink自带的滑窗实现,例如定义步长为50ms的窗口会非常导致巨大的负载。
4、另外,使用滑窗做统计量计算还有一个过期时间存在误差的问题,这个问题在下面会详细讨论。
Flink提供的ProcessFunction本身并不是窗口,它的功能比滑窗更底层。虽然它本身是无状态的,但可以在代码中自定义地为其添加状态,因此可以把ProcessFunction作为有状态的窗口来使用。
Flink提供了MapState类用于保存ProcessFunction的状态,它可以这样定义: MapState<UK, UV> windowState
之后向其中添加/更新状态: windowState.put(key, value)
ProcessFunction能够解决复数滑窗导致的资源浪费问题,对一个key只会构造一个它的实例。也因此ProcessFunction不仅要接受新到达的数据,同时它还得不断地对过期旧数据进行清理:

可以看出,这就需要ProcessFunction保存接受到的原始数据。这是否会导致内存的消耗增加?当然这里存在一个权衡,不过总的来说和滑窗方案相比,我认为ProcessFunction对性能的影响应该是正面的。这是因为:
1、本身复数个滑窗所保存的状态也会占用较多的内存,在步长较小时,存很多窗口状态可能比原始数据的占用空间更大;
2、滑窗的创建和销毁导致很高的并发数,并且在下一轮窗口创建时,上一轮窗口的产生的CPU负载可能还未被完全消化,导致CPU性能雪崩问题。而ProcessFunction可以避免此问题。
如果非常在意保存原始数据所消耗的内存空间,那么还可以在牺牲一定精度的情况下采用分桶的策略:新数据到达时进行部分聚合。例如对一个长度为10分钟的窗口,每分钟分为一桶,这样窗口中只需要存10份子状态,每分钟清理一个桶即可,而不再需要保存原始数据:

虽然我们把ProcessFunction当作一个窗口在用,但它本质上是一个应用于流数据的函数,因此并不需要定义trigger之类的窗口触发器,只要在需要输出的地方用 out.collect() 将结果输出到流即可。
如果我们定义在新数据到达后立刻更新状态并且输出新状态,在Flink上游数据更新非常快的情况下,和滑窗策略相比可能下游的IO压力(峰值TPS)会增加。这是因为滑窗对输出的频率天然是有控制的(步长),而ProcessFunction则没有。
不过总的来说,我认为使用ProcessFunction依然会有利于减少下游的IO压力,这是因为上面提到过,滑窗方案浪费了很多IO资源在重复的输出上,而ProcessFunction则不会出现重复输出相同值的问题。如果确实非常在意峰值TPS,那么可以用和上面类似的分桶策略进行ProcessFunction的结果输出,这样就能够和滑窗一样控制输出频率。
此外,ProcessFunction可以避免上面提到过的,滑窗输出的统计量过期时间误差的问题。首先看一下这个问题是什么:
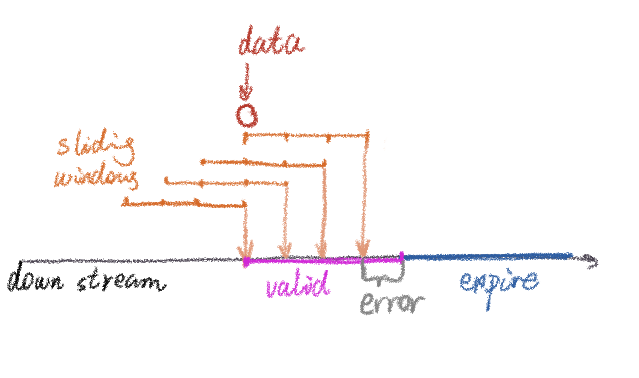
图中采用滑窗的方案,例如滑窗长度3分钟,步长1分钟。统计量是前三分钟内的计算结果,例如前三分钟内的数据和。在一条数据到达之后,上面解释过,会产生四个滑窗(以黄色表示)。Flink的下游(例如存到Redis)总共会接受到4次相同的更新。在最后一次更新之后,这个统计量应该立刻失效。但问题是如果不传输额外数据的话,下游并无法判断那一次更新是最后一个窗口的输出。下游能采用的最佳策略是,如果经过一个步长的时间(这个例子是1min)还没有接收到新数据的话,就认为上一次的更新是最后一个窗口的输出。因此下游可以将统计量的失效时间配置为步长。
但这样就会导致一个步长时间的误差,也就是图中的灰色error部分。在这一分钟里,实际距离data的到达已经超过了一分钟,但是仍然能够从Redis读取到这个统计量。另外,实际系统中失效时间应该配置得比窗口步长更长一些,否则如果其中一个窗口计算的结果存在延迟,就会导致下游一小段没有数据的时间。但失效时间设置得越长,上面提到的误差也就越大。
如果改用ProcessFunction的方案,则对统计量失效的控制会十分简单,只需要将失效时间配置为“窗口”长度即可:
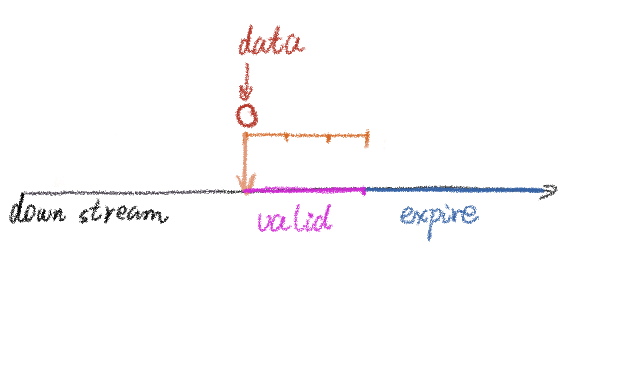
可以看到,此方案的优点是可控程度高,各种优化都可以通过代码定制实现,这得益于ProcessFunction是Flink很底层的方法。但缺点也很明显:使用ProcessFunction不仅要编码实现计算逻辑,还要手动维护和清理状态,增加了需要编写的代码量。
Feel free to comment by raising an issue .