2021-04-22
< view all posts联邦学习是一种分布式学习技术,可使多方在保证数据隐私的同时共同建模,打破数据孤岛。在AI应用中,数据的质量是保证建模效果的关键,但很多企业面临数据量少、局部性强的问题。如果多家企业能够分享数据联合建模,有希望能获得效果更好的模型。但这样做就要求各家企业都将数据集中转存到一个数据中心,从而进行统一的建模。而这种数据外流和分享对商业公司而言往往非常敏感,难以实现。
联邦学习就是为了避免原始商业数据的外流,将模型训练保留在各参与方的本地进行,同时参与方之间通过训练过程的信息交换,对模型进行更新,达到共同训练和优化模型的效果。
联邦学习可以分为横向、纵向和迁移三种。其中横向和纵向与我们场景最为相关,它们两者的区别在于:
1、横向联邦学习对齐特征、扩充数据;纵向联邦学习对其数据、扩充特征。举例来说,例如银行A和银行B主要分布在不同地区,它们的用户id差别较大,但是因为交易数据的维度是类似的,它们能够提取到同一批特征,那么就可以使用横向联邦学习。而另一种情况,例如某银行和某大商户进行联邦学习,因为双方可能各自掌握一些独有的数据维度,会设计出不同的特征,就必须使用纵向联邦学习。
2、横向联邦学习,在建模完成后参与各方均持有完整模型,可以独立进行预测;纵向联邦学习,在建模完成后参与各方各自持有一个不完整的模型,需要协作进行预测;
3、横向联邦学习,参与方的数据应自带标签;纵向联邦学习,只需要一个参与方持有数据标签:因为横向联邦学习是对数据的扩充,如果扩充的数据没有标签那么就很难利用;而纵向联邦学习的数据是对齐的,只需要一方拥有标签就可以进行。

例如,上图是横向联邦学习的例子,红色框中的数据用于建模。框中的数据,特征维度是在A和B都存在的;部分数据是由A提供的,部分数据是由B提供的。

上图是纵向联邦学习的例子,红色框中的数据用于建模。框中的数据(id)是在A和B都存在的;而部分特征是由A提供的,部分特征是由B提供的。
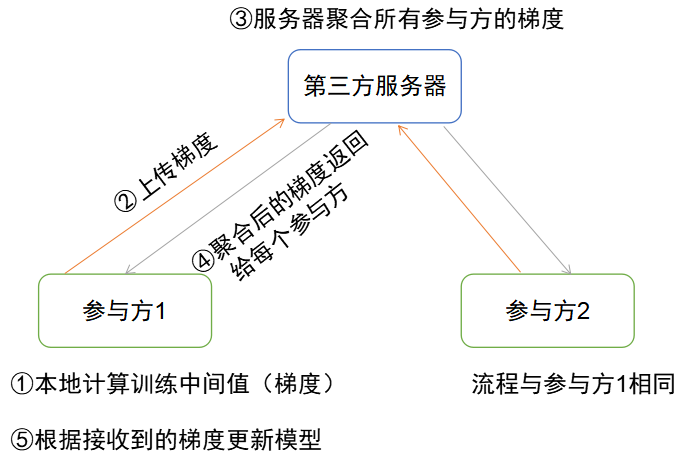
横向联邦学习的原理比较简单,参与方只需要在本地的数据集上进行模型训练,之后相互交换模型训练的中间值(梯度)。主流的设计是由一个独立的第三方服务器(联邦学习平台)去收集每个参与方上传的中间值,进行聚合计算后再回传给每个参与方,让参与方更新模型。
整个过程中所有参与方获得的模型都是相同的。
有时候可能会出现这样的理解:两个公司互相之间达成协议,其中一个公司同时作为建模的参与方和平台方(上图中的第三方服务器),将系统结构简化为两方间的交互。
但是这样的结构设计是存在问题的:无论是横向还是纵向联邦学习,由同一个主体同时担任参与方和平台方会削弱系统的安全性,并且削弱同态加密的意义:因为平台方持有同态加密的私钥,所有的加密内容对平台方实际上是透明的。因此为了保证系统的安全性,需要阻断平台方感知参与方的模型或数据。
一旦平台方和某个参与方之间存在信息泄露,虽然其它参与方只暴露了模型训练过程的中间值,但通过特定的攻击手段,仍然能够从这些中间值中推断出关于原始数据的部分信息。(Privacy-Preserving Deep Learning via Additively Homomorphic Encryption, 2018)
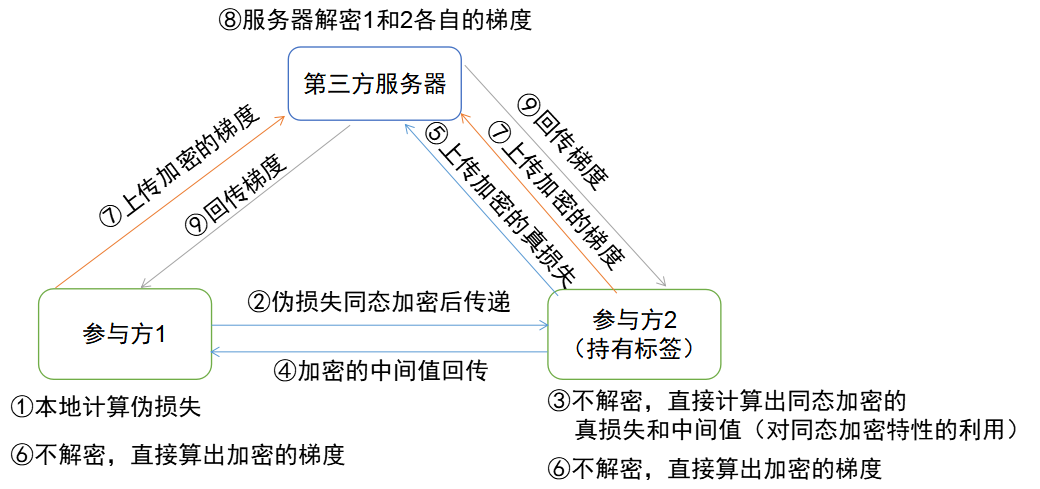
纵向联邦学习的结构比横向复杂一些,基于两个原因:
为了实现(1),纵向联邦学习中的平台方会分别计算每个子模型的梯度,分发给对应的参与方。子模型的梯度是互相隔离的,因此一个参与方无法感知其它参与方的梯度。
为了实现(2),所有未持有标签的参与方会将本地的预测结果在同态加密后传递给持有标签的那个参与方,再通过持有标签的参与方返回的值来算出(被同态加密的)梯度,最后所有梯度上传至平台方,由平台方解密并回传。
具体公式可以参见Federated Machine Learning: Concept and Applications
因为每个参与方只有子模型,在预测时必须要由每个参与方分别算出自己的预测结果,同态加密后传到第三方,由第三方解密并聚合之后得到最终的预测结果。
在纵向联邦学习中,每个参与方的数据、模型、中间值(损失和梯度)都是完全隔离的,因此安全性比横向联邦学习会更好一些。(横向联邦学习的参与者理论上可以通过生成式对抗网络发起攻击,重建其它参与者的部分原始数据:Deep Models Under the GAN: Information Leakage from collaborative Deep Learning, 2017)
隐私计算的目标是实现数据的“可用不可见”。实现“不可见”有几种常见的思路:
对加密而言,加密后的数据实现了“不可见”,但是如何实现“可用”呢。这是由同态加密的特点保证的:这种特殊的加密方法使先计算后加密的结果等于先加密后计算的结果。举例来说,例如有式 a + b = c,在对a和b加密后得到 a’ 与 b’。对一般的加密方法,a’和b’的值是无法用来计算的,而对同态加密,仍然能进行与相加等效的运算 a’ +’ b’,并且这个运算的结果和直接加密 c 得到的 c’ 是相同的。
通过同态加密,能够使计算者在不解密数据的情况下对数据进行正确的计算(如加法和乘法),并且得到的结果也是加密的。
差分隐私技术通过在数据中添加噪声或对敏感数据进行泛化的方式,让敏感信息模糊化。
一个例子是Google在最早的联邦学习实践中,在每个手机设备上训练一个模型,为了保证个人数据的隐私性,Google规定了必须有至少几百或几千个设备同时在线时,才进行训练,训练过程只使用这些数据的平均值,从而实现对个人数据的模糊化。
秘密共享技术将秘密进行拆分,由不同的主体管理,达到单个主体无法恢复秘密信息的效果。并且提供一定的容错性,在部分主体出现问题时仍然能够完整地恢复数据。
在联邦学习中,秘密共享主要解决第三方服务器不可信的问题。在上面举例的系统结构中,都只有一个第三方服务器,并且所有参与者都默认这个第三方是可信的。这个假设存在一定的安全风险。可用利用秘密共享技术,添加更多的彼此独立的第三方服务器,每个参与者将自己的数据拆开,只给每个第三方发送一部分信息,从而降低安全风险(可参考 Privacy-Preserving Distributed Machine Learning based on Secret Sharing)。
在各种主流的建模框架中,TensorFlow对联邦学习支持最好(因为联邦学习本身就是由Google提出并最早投入生产使用的)。TensorFlow提供了TFF(TensorFlow Federated)框架,可以直接通过此框架的API开发联邦学习模型,并且通过部署TFF来进行联邦学习训练。
但需要注意的是,尽管TFF提供了联邦学习建模API,但是因为这个框架仍在开发中,并未完全集成相应的隐私计算技术(同态加密等),因此仍需要手动实现对传输内容的同态加解密,或者由联邦学习平台进行。
XGBoost用于联邦学习目前没有官方实现,有一些开源的社区实现,包括加州大学伯克利分校的Federated XGBoost。这个社区实现提供了可用的API和文档,能够用于模型开发。
另外从原理上来说,XGBoost支持联邦学习,并且因为XGBoost支持基于直方图的Greadinet Boost优化(通过区间化降采样加快树的创建),XGBoost联邦学习理论上可以取得与单机学习相同的效率。
PyTorch用于联邦学习目前也没有官方实现,有一些开源实现,但主要是对学术成果的复现,其中验证了一些简单模型利用PyTorch联邦学习的可行性,但未覆盖所有模型。
Feel free to comment by raising an issue  .
.